








[ad_1]
Are you uninterested in robotic sounding text-to-speech purposes? Nicely, Microsoft has some thrilling information for you! They’ve simply introduced VALL-E, an AI mannequin that may carefully mimic an individual’s voice with solely a three-second audio pattern. This expertise not solely replicates the sound of an individual’s voice but in addition makes an attempt to protect the speaker’s emotional tone.
The chances for VALL-E are countless, from high-quality text-to-speech purposes to speech modifying and audio content material creation when paired with different AI fashions like GPT-3 and ChatGPT. Microsoft has categorised VALL-E as a “neural codec language mannequin” and it’s primarily based on a expertise referred to as EnCodec, which was introduced by Meta in October 2022.
Not like conventional text-to-speech strategies that depend on waveform manipulation, VALL-E generates discrete audio codec codes from textual content and acoustic prompts. It analyzes the way in which an individual sounds, breaks that data into discrete elements, and makes use of coaching information to match how that voice would sound if it spoke different phrases past the three-second pattern.
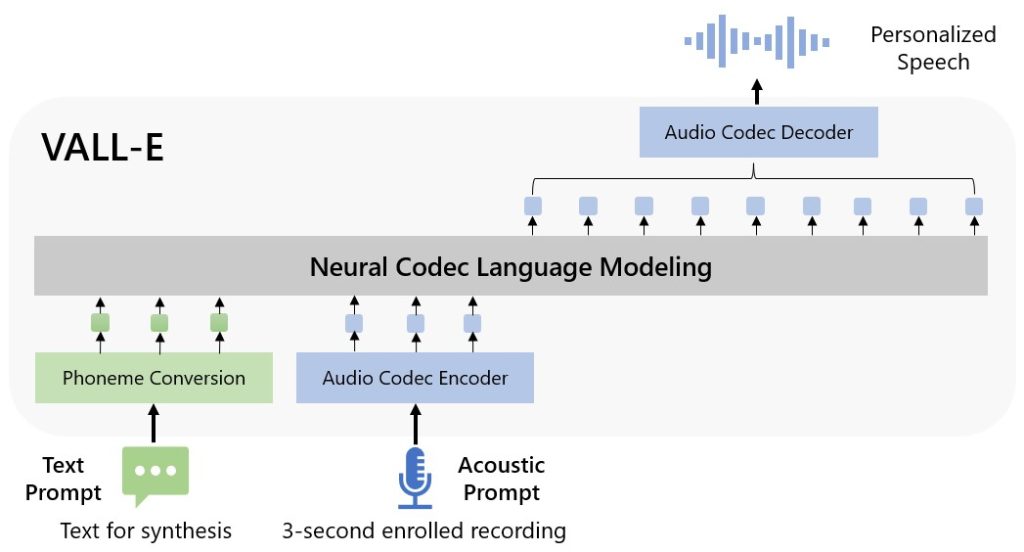
The outcomes of this revolutionary expertise are combined, with some samples sounding machine-like and others being virtually indistinguishable from an actual human voice. You possibly can take heed to the samples your self on the VALL-E analysis web page: https://valle-demo.github.io/. The truth that it preserves the emotional tone of the unique samples is what units it aside from earlier text-to-speech fashions. VALL-E additionally precisely matches the acoustic surroundings, that means if the speaker recorded their voice in an echo-y corridor, the VALL-E output may also sound prefer it got here from the identical place.
Microsoft plans to proceed bettering the mannequin by scaling up its coaching information and discovering methods to scale back unclear or missed phrases. Whereas VALL-E does pose a menace to voice actors and narrators, it additionally affords a brand new degree of personalization and connection for individuals who wish to preserve the reminiscence of a liked one’s voice alive. The Microsoft VALL-E group has added an ethics assertion on their demonstration web page, acknowledging the potential implications of this expertise when utilized to unseen audio system. They stress the significance of guaranteeing the speaker agrees to any modifications and having methods in place to detect edited speech.
The world of AI is consistently advancing, and VALL-E is simply the newest instance of how expertise can bridge the hole between the previous and the current. It affords a brand new degree of text-to-speech that was beforehand unattainable. We are able to’t wait to see the way it will advance and be used sooner or later!
[ad_2]
Source link



{kind=link}